Introduction
Test-Driven Development (TDD) is a software development approach in which test cases are developed to specify and validate what the code will do. In simple terms, test cases for each functionality are created and tested first and if the test fails then the new code is written in order to pass the test and make the code simple and bug-free.
Test-Driven Development starts with designing and developing tests for every small functionality of an application. TDD instructs developers to write new code only if an automated test has failed. This avoids duplication of code.
The simple concept of TDD is to write and correct the failed tests before writing new code (before development). This helps to avoid duplication of code as we write a small amount of code at a time in order to pass tests. (Tests are nothing but requirement conditions that we need to test to fulfill them).
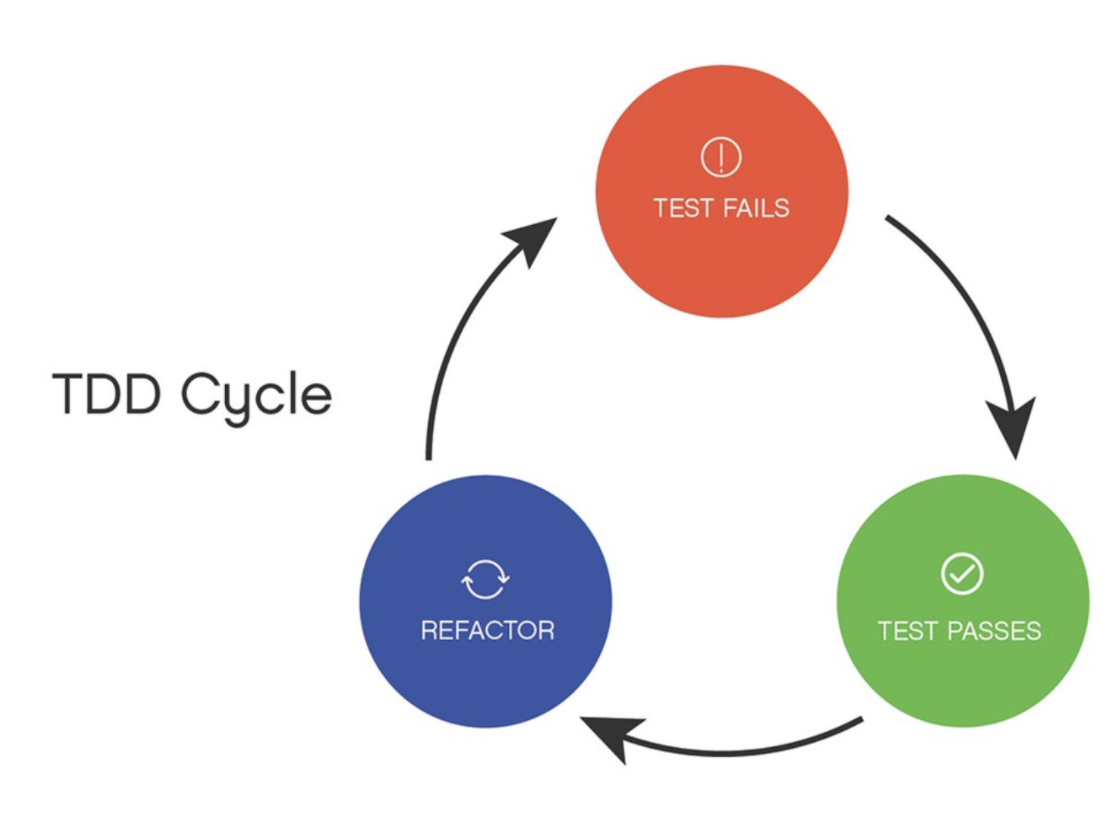
-
Red color represents: The unit tests written that fail at first. If the tests do not fail, that means that the base functionality is present already - then why do we need tests, to begin with?
-
Green color is: The production code you write to get the test to pass as soon as possible.
-
Blue color represents: The refactor element is about changing the code to make it right; until all of the tests pass. The cycle should last no more than ten minutes, and the idea is that you are staying succinct in what you want for your features, and you can gain confidence in refactoring because you know that everything will work as long as it continues passing the regression tests
Glossary
When it comes to automated testing, TDD, unit testing, there are many terminologies that pop up. In the section, the most important terms are introduced that are used and adapted in EasyJet.
CI-CD
Continuous integration (CI) and continuous delivery (CD) embody a culture, set of operating principles, and collection of practices that enable application development teams to deliver code changes more frequently and reliably. The implementation is also known as the CI/CD pipeline.
CI/CD is one of the best practices for DevOps teams to implement. It is also an agile methodology best practice, as it enables software development teams to focus on meeting business requirements, code quality, and security because deployment steps are automated.
As explained already, the terms CI/CD stands for Continuous Integration and Continuous Delivery – Deployment.
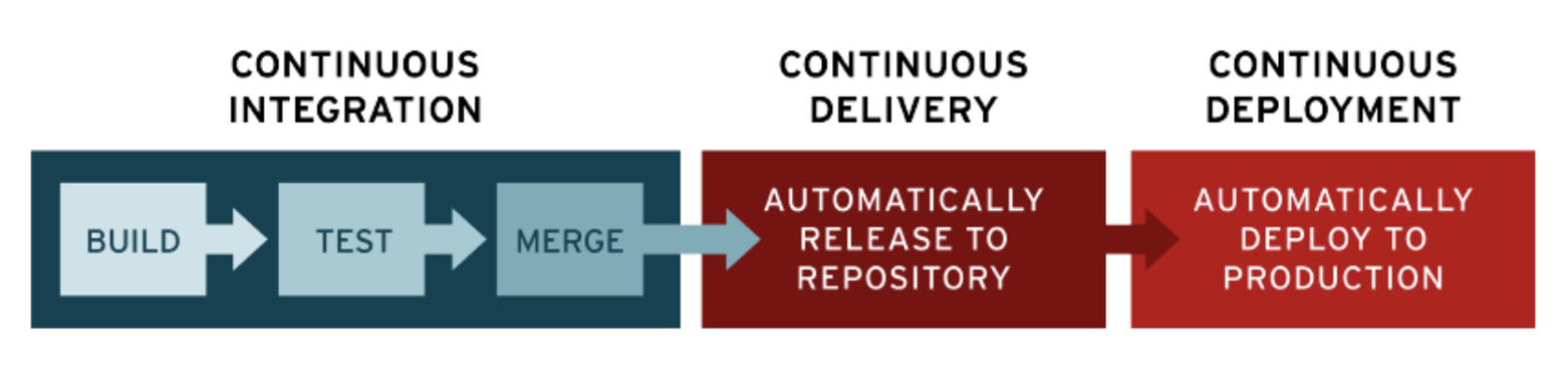
Continuous Integration
Continuous integration is a development process where you integrate your changes to the git repository by doing a commit and push frequently. In ML, when you want to retrain your model, you will first create a branch, train a model and commit changes to the branch. If you have CI set up, then an automated process would build your code, run tests. Successful CI means new code changes to an app are regularly built and tested.
In other words, the technical goal of CI is to establish a consistent and automated way to build, package, and test applications.
Continuous Delivery
Continuous delivery picks up where continuous integration ends. In continuous delivery, if the changes from CI are successfully built and tested, then CD would deliver the code to the shared repository. The shared repository would have the new code/model that the rest of the team members could access. The goal of continuous delivery is to have a codebase that is always ready for deployment to a production environment.
Type of Tests
Through the CI/CD, there was a discussion of creating tests to automatically check the robustness of the code.
This pyramid is a representation of the types of tests that you would write for an application.
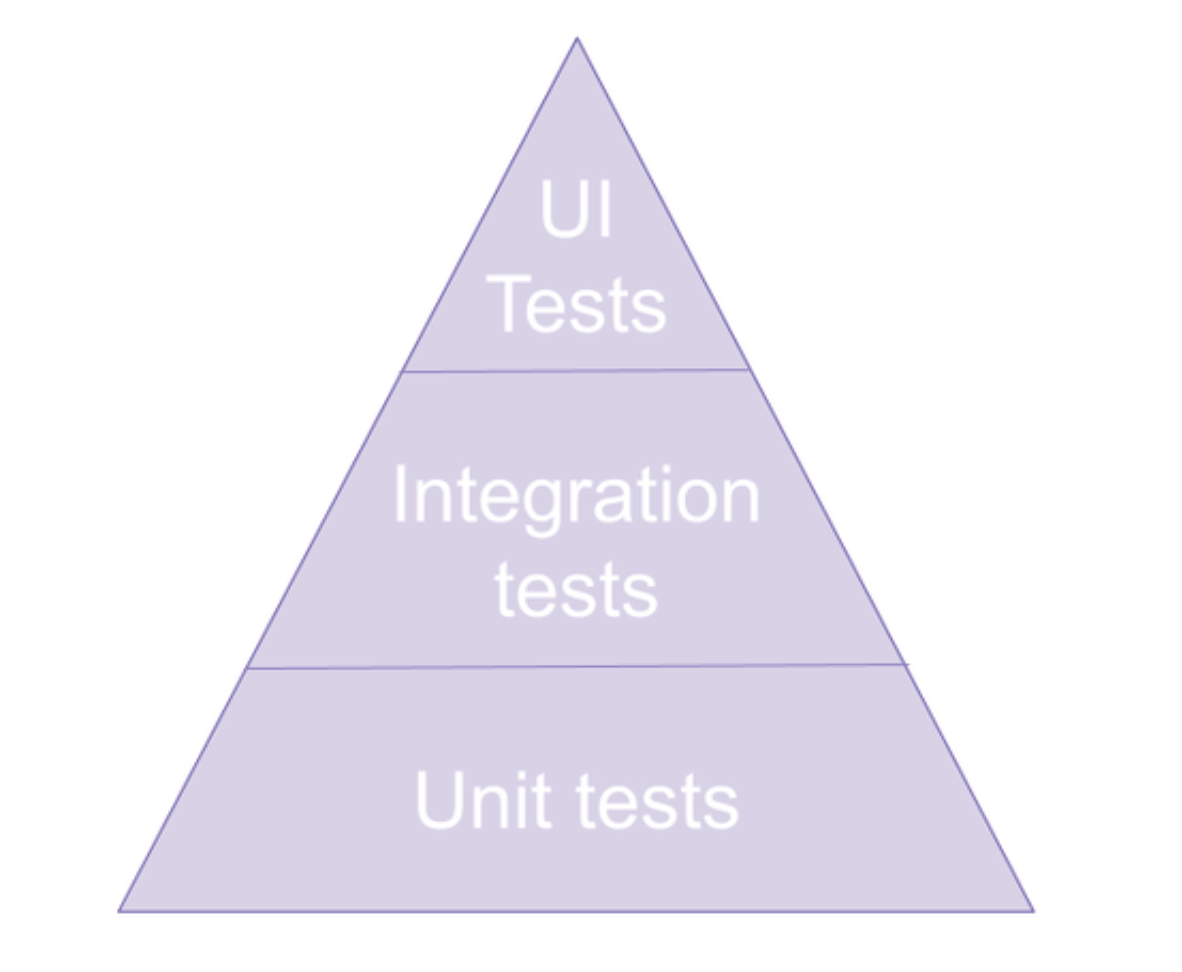
Unit Tests
It is a piece of code that invokes another piece of code (unit) and checks if the output of that action is the same as the desired output.
Unit tests ensure that a section of an application (known as the “unit”) meets its design and behaves as intended. In procedural programming, a unit could be an entire module, but it is more commonly an individual function or procedure. In object-oriented programming, a unit is often an entire interface, such as a class, but could be an individual method.
By writing tests first for the smallest testable units, then the compound behaviors between those, one can build up comprehensive tests for complex applications.
Integration Tests
Integration tests aim to determine whether modules that have been developed separately work as expected when brought together.
In terms of a data pipeline, these can check that:
- The data cleaning process results in a dataset appropriate for the model
- The model training can handle the data provided to it and outputs results (ensuring that code can be refactored in the future)
UI Tests
It is testing does the system fulfill expected business and contract requirements. It is considering the system as a black box.
For example:
- Ensure that the values produced by the model make sense in terms of the industry.
- Ensure that the model actually helps the product solve the problem at hand.
- Provide visibility of the ML components of the product in a common language understood by clients, product managers and engineers in the same way.
TDD Best Practices
Despite the helpfulness of TDD, it is not always advisable to use TDD as it requires a lot of time to generate and refactor the necessary tests. This is why it is important to know when it would be beneficial to start writing tests for our data products and when it is not worth it.
TDD is great in these cases:
- Analytics pipeline
- Complicated proof of concept, i.e. different ways to solve a sub-problem, clean data, etc.
- Working with a subset of data, so you have to make sure that you capture problems when new issues come up without destroying the working code.
- You are working in a team, yet you want to make sure that no one breaks the functioning code.
TDD is probably not worth the effort in the following scenarios:
- You are exploring a data source, especially if you do it to get an idea of the potential and pitfalls of said source.
- You are building a simple and straightforward proof of concept. Your goal is to evaluate whether further efforts are promising or not.
- You are working with a complete and manageable data source.
- You are (and you will be) the only person who is working on a project. This assumption is stronger than it might appear at first glance but holds for ad-hoc analyses.
Methodology
Like all the different frameworks, TDD follows a specific methodology when it comes to creating the tests. This is known as the AAA structure.
AAA stands for Arrange, Act and Assert.
- Arrange:
Organizing the data needed to execute the required piece of code. This is the input. - Act:
Executing the code being tested; exercise the behavior - Assert:
After the execution of the code, check if the result (output) is the same as the one that was expected.
TDD Rules
When following the TDD approach, please follow the rules highlighted below:
-
TDD rule number 1:
Test first, code later. -
TDD rule number 2:
Add the reasonably minimum amount of code you need to pass the tests. -
TDD rule number 3:
You shouldn’t have more than one failing test at a time. -
TDD rule number 4:
Write code that passes the test. Then refactor it. -
TDD rule number 5:
A test should fail the first time you run it. If it doesn’t, ask yourself why you are adding it. -
TDD rule number 6:
Never refactor without tests.
Pytest
Pytest is a testing framework that allows us to write test codes using python. We can write code to test anything like database, API and even UI if needed. It is wide commong for corporations and Data Science teams to use pytest to write tests for the Machine Learning pipelines.
Some of the advantages of pytest are:
- Very easy to start with because of its simple and easy syntax.
- Can run tests in parallel.
- Can run a specific test or a subset of tests
- Automatically detect tests
- Open-source
There are two main guidelines needed to use it from the functional points of view (mport the module and test suffix)
- Import the module using python:
import pytest -
Create a test .py script starting with the “test_*.py” prefix: “test_my_function.py”
- Use the “assert” command in python to evaluate the output of your test:
def test_function_increment(): x=5 y=6 assert x+1 == y, "test failed"
Useful Decorators
- @pytest.fixture Pytest fixtures are functions that create data or initialize some system state for the test suite. Any test that wants to use a fixture must explicitly accept it as an argument.
The idea behind fixtures is that when creating test data cases we would often want to run some code before every test case to get the corresponding data. Instead of repeating the same code in every test, we create fixtures that establish a baseline code for our tests. In other words, the data that you create as input is known as a fixture. It’s common practice to create fixtures to initialize database connections, load data, or instantiate classes and reuse them.
Example:
For unit testing purposes, we might want to create some dummy data to test if our units (functions) work as expected. Instead of calling the same data through a function in every single test, we would like to call it once and use the @pytest.fixture decorator instead.
Consider we have a project template structure as shown:
src/
├────config/
…
├──── sql/
└────tests/
Within the tests/ folder, there can be a conftest.py script (along with the remaining test_*.py scripts) that loads the data as per the example shown:
- conftest.py
import pytest
@pytest.fixture
def supply_AA_BB_CC():
aa=25
bb=35
cc=45
return [aa, bb, cc]
- test_basic_fixture.py
import pytest
def test_comparewithAA_file(supply_AA_BB_CC):
zz=25
assert supply_AA_BB_CC[0]==zz,"aa and zz comparison failed"
def test_comparewithBB_file(supply_AA_BB_CC):
zz=25
assert supply_AA_BB_CC[1]==zz,"bb and zz comparison failed"
def test_comparewithCC_file(supply_AA_BB_CC):
zz=25
assert supply_AA_BB_CC[2]==zz,"cc and zz comparison failed"
pytest will look for the fixture in the test file first and if not found it will look in the conftest.py. For more thorough documentation of fixtures, please refer to the official pytest documentation.
- @pytest.mark.parameterize
If you’re running the same test and passing different values each time and expecting the same result, this is known as parameterization.
Parameterize extends a test function by allowing us to test for multiple scenarios. We simply add the parametrize decorator and state the different scenarios.
Example:
A straightforward example using parameterize is from the following example taken from the official pytest documentation.
# content of test_expectation.py
import pytest
@pytest.mark.parametrize("test_input,expected", [("3+5", 8), ("2+4", 6), ("6*9", 42)])
def test_eval(test_input, expected):
assert eval(test_input) == expected
Example:
For instance, imagine we are having a pd.DataFrame (df) and we have to test if a specific function we ran before for a subset of our columns has the expected outcome. We want to run this for a series of columns.
Instead of creating a single test for every single column, we can use the @pytest.mark.parameterize decorator to parallelize our test for each column; col1, col2, col3
import pytest
@pytest.mark.parametrize("df, col",[(df,'col1'),(df,'col2'),(df,'col3')])
deftest_non_zero_values(df,col):
""" Test there are no negative values in the created columns """
assert df[col].min()>=0
Conclusion
Testing an ML learning pipeline is relatively different from the traditional creation of software as used in software development. Due to this, there is a misconception that data science components cannot be put through automated testing. Although some parts of the pipeline can not go through traditional testing methodologies due to their experimental and stochastic nature, most of the pipeline can.

Useful Resources
https://towardsdatascience.com/tdd-datascience-689c98492fcc
https://medium.com/swlh/learning-to-love-tdd-f8eb60739a69
https://python-bloggers.com/2020/08/how-to-use-ci-cd-for-your-ml-projects/
https://www.redhat.com/en/topics/devops/what-cicd-pipeline
https://rubikscode.net/2019/03/04/test-driven-development-tdd-with-python/
https://code.likeagirl.io/in-tests-we-trust-tdd-with-python-af69f47e6932
https://realpython.com/python-testing/
https://realpython.com/pytest-python-testing/
https://www.guru99.com/pytest-tutorial.html
https://www.guru99.com/test-driven-development.html
https://towardsdatascience.com/unit-testing-for-data-scientists-dc5e0cd397fb
https://intothedepthsofdataengineering.wordpress.com/2019/07/18/testing-your-machine-learning-ml-pipelines/
https://www.thedigitalcatonline.com/blog/2020/09/10/tdd-in-python-with-pytest-part-1/
https://docs.pytest.org/en/stable/fixture.html
https://cloud.google.com/solutions/machine-learning/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning